Transformer Architecture
Transformer Architecture is a neural network design introduced in the 2017 paper 'Attention Is All You Need' that processes sequences by computing attention weights between every pair of tokens in parallel; Each transformer layer contains a multi-head self-attention block and a feed-forward network; Builders rarely implement transformers directly; they consume pretrained checkpoints via APIs or frameworks like Hugging Face Transformers
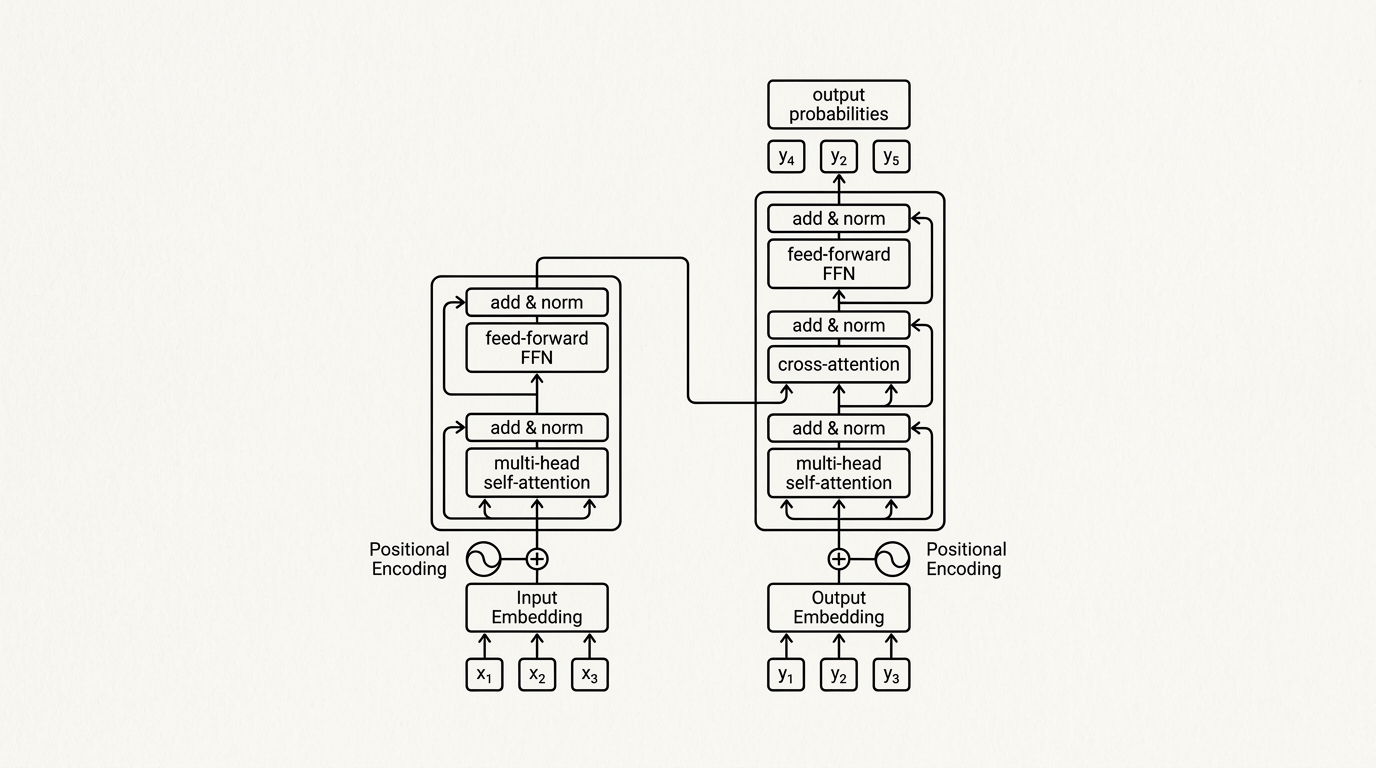
Transformer Architecture is a neural network design introduced in the 2017 paper ‘Attention Is All You Need’ that processes sequences by computing attention weights between every pair of tokens in parallel. This design enabled much faster training than recurrent networks and scales efficiently with additional compute, making it the dominant architecture for large language models.
How it works
Each transformer layer contains a multi-head self-attention block and a feed-forward network. Self-attention lets every token attend to every other token in the context window, capturing syntax, coreference, and long-range dependencies in a single pass. Stacking many such layers produces increasingly abstract representations that the final layers use to predict output tokens.
Key facts
- Origin paper: Vaswani et al., Google Brain, NeurIPS 2017.
- Key operation: Scaled dot-product attention, computed as softmax(QKT / sqrt(d_k))V.
- Variants: Encoder-only (BERT), decoder-only (GPT), and encoder-decoder (T5) are the three main families.
- Scaling: Transformer performance follows predictable scaling laws with respect to parameters, compute, and data.
For builders
Builders rarely implement transformers directly; they consume pretrained checkpoints via APIs or frameworks like Hugging Face Transformers. Understanding the architecture helps diagnose context window limits, attention cost, and why long-context inference is disproportionately expensive compared to short-context calls.
Sources
- Vaswani, A., et al. (2017). Attention Is All You Need. arXiv:1706.03762. arxiv.org
- Brown, T., et al. (2020). Language Models are Few-Shot Learners (GPT-3). arXiv:2005.14165. arxiv.org
- Bommasani, R., et al. (2021). On the Opportunities and Risks of Foundation Models. Stanford CRFM. arxiv.org
- NIST. (2023). AI Risk Management Framework (AI RMF 1.0). nist.gov
- Stanford HAI. Foundation Models research portal. hai.stanford.edu