Top-p Sampling
Top-p Sampling is a token selection method that, at each generation step, considers only the tokens whose cumulative probability mass sums to at least p, then samples from that nucleus; The model sorts all vocabulary tokens by descending probability, then accumulates probabilities until the running total reaches p; Most production LLM API calls expose both temperature and top_p parameters
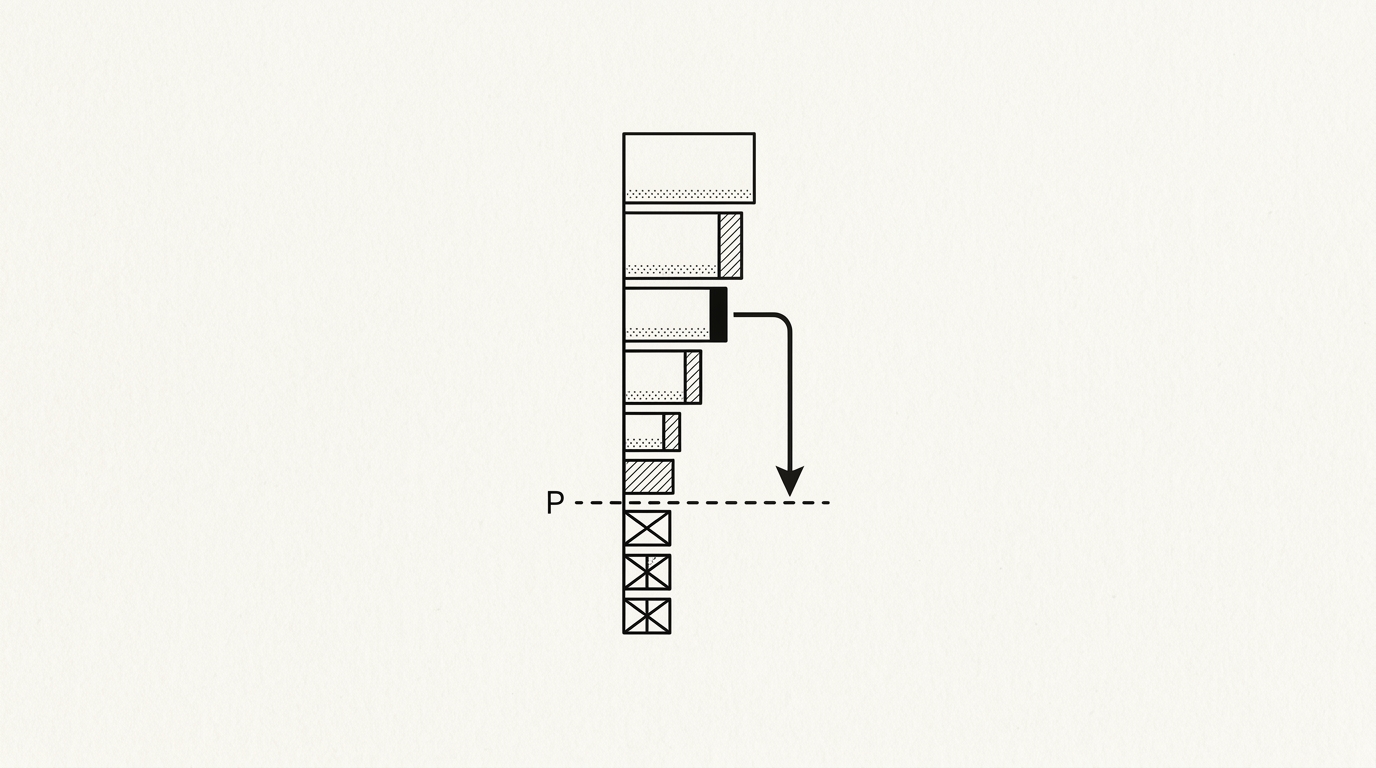
Top-p Sampling is a token selection method that, at each generation step, considers only the tokens whose cumulative probability mass sums to at least p, then samples from that nucleus. Unlike top-k sampling, which always considers the same fixed number of tokens, top-p dynamically adjusts the candidate pool size based on how concentrated the model’s distribution is.
How it works
The model sorts all vocabulary tokens by descending probability, then accumulates probabilities until the running total reaches p. Only tokens in that prefix set are eligible for sampling; the rest are zeroed out and the remaining distribution is renormalized before drawing. When the model is confident, the nucleus is small; when uncertain, it widens to include more options.
Key facts
- Common defaults: p values of 0.9 to 0.95 are typical; 1.0 disables the filter entirely.
- Proposed by: Holtzman et al. in ‘The Curious Case of Neural Text Degeneration’ (2019).
- Interacts with temperature: Temperature rescales logits before top-p is applied, so both parameters jointly shape the sampling behavior.
- Top-k comparison: Top-k fixes the candidate count; top-p fixes the probability mass, making it more adaptive.
For builders
Most production LLM API calls expose both temperature and top_p parameters. For factual tasks, setting top_p to 1.0 and temperature to 0 is common. For generation tasks, a top_p of 0.9 with a moderate temperature provides a good balance between coherence and variety. Avoid tuning both simultaneously without systematic evals, as their interaction can be difficult to predict.
Sources
- Wei, J., et al. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. arXiv:2201.11903. arxiv.org
- Brown, T., et al. (2020). Language Models are Few-Shot Learners. arXiv:2005.14165. arxiv.org
- Anthropic. Prompt engineering best practices. anthropic.com
- OpenAI. Prompt engineering guide. platform.openai.com
- NIST. (2023). AI Risk Management Framework. nist.gov