Batch Inference
Batch Inference is an asynchronous inference pattern where a large set of prompts is submitted to an inference provider in a single batch job, processed over a period of minutes to hours, and results are returned when the job completes; The client uploads a JSONL file of requests or submits an array of prompts through a batch API endpoint; Batch inference is the right choice for any non-interactive AI workload where latency does not matter: generating embeddings for a document corpus, running evals over a dataset, classifying historical records, or preparing training data
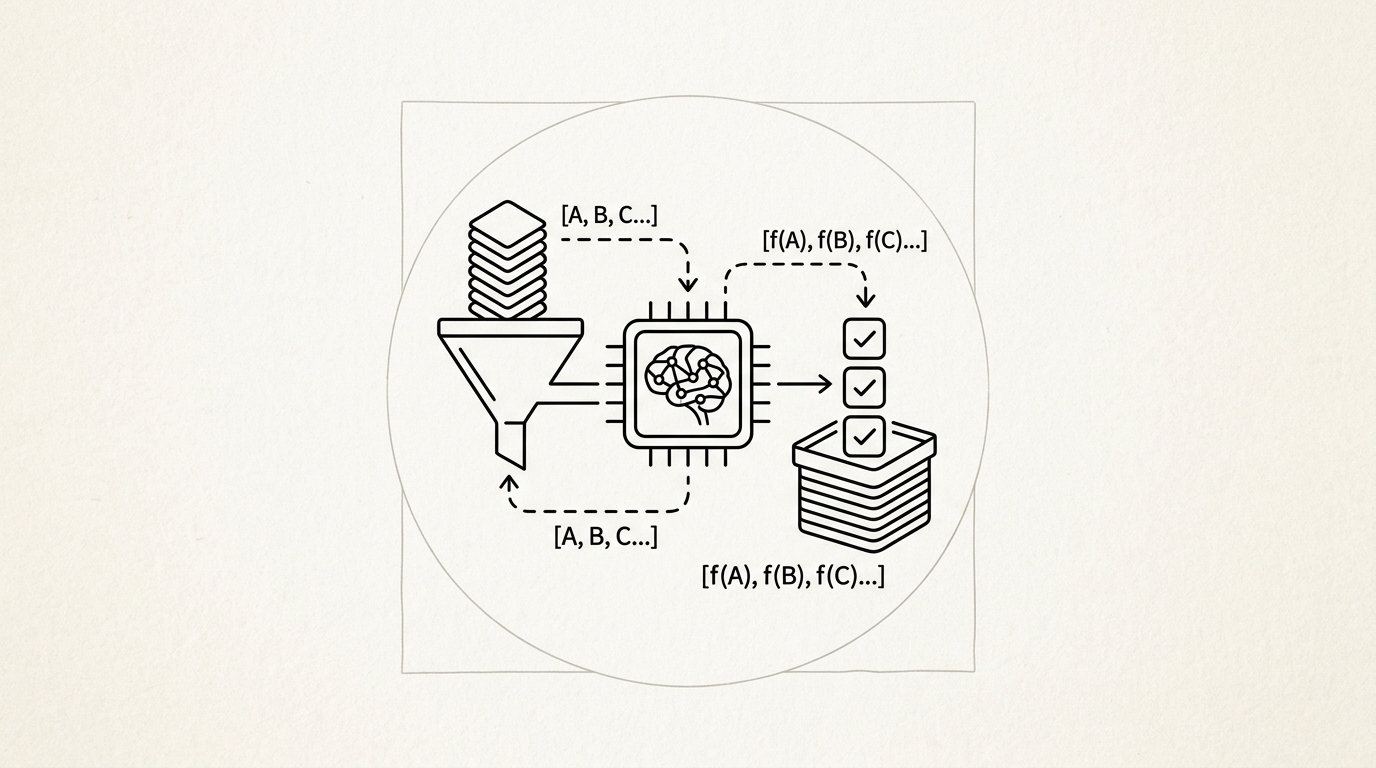
Batch Inference is an asynchronous inference pattern where a large set of prompts is submitted to an inference provider in a single batch job, processed over a period of minutes to hours, and results are returned when the job completes. Providers offer batch pricing at 50 percent or more below standard synchronous API rates in exchange for relaxed latency SLAs.
How it works
The client uploads a JSONL file of requests or submits an array of prompts through a batch API endpoint. The provider queues the batch and processes requests using spare capacity, typically completing jobs within a few hours. Results are returned as a JSONL file or stored object that the client polls or is notified about upon completion.
Key facts
- Pricing: Anthropic and OpenAI both offer batch APIs at roughly 50 percent off synchronous pricing.
- Latency SLA: Batch jobs typically complete within 24 hours; actual latency is often 1 to 4 hours for large jobs.
- Use cases: Document classification, embedding generation, dataset annotation, and offline evaluations are ideal batch workloads.
- Limits: Batch job size is capped by providers; very large jobs must be split across multiple batch submissions.
For builders
Batch inference is the right choice for any non-interactive AI workload where latency does not matter: generating embeddings for a document corpus, running evals over a dataset, classifying historical records, or preparing training data. Moving these workloads from synchronous to batch API calls typically halves inference costs with no engineering complexity beyond changing the API call pattern.
Sources
- Zhao, W. X., et al. (2023). A Survey of Large Language Models. arXiv:2303.18223. arxiv.org
- Yu, G., et al. (2022). Orca: A Distributed Serving System for Transformer-Based Generative Models. OSDI. usenix.org
- Kwon, W., et al. (2023). Efficient Memory Management for LLM Serving with PagedAttention. vllm-project. github.com
- Anthropic. Claude API documentation. docs.anthropic.com
- OpenAI. API reference. platform.openai.com